Data Science with Spark
DATA SCIENCE AND APACHE SPARK
Data Science has transformed the world. It has contributed towards the excessive growth of data and to develop intelligent systems. To analyze large amounts of data, various Data Science tools are available to Data Scientists. Among several available tools, Apache Spark has revolutionized the Data Science industry in a great manner.
Apache Spark
Spark is one of the open-source which is capable to process huge amount of data efficiently with very high speed. Due to its data streaming capability, Spark has left behind the other existing Big Data platforms. It also carry out machine learning operations and SQL workloads that allow us to access the datasets. Spark is developed on application levels through multiple languages like Python, Java, R, and Scala.
Components of Apache Spark for Data Science
Main components of Spark are – Spark Core, Spark SQL, Spark Streaming, Spark MLlib, Spark R and Spark GraphX.
SNo | Components | Description |
1 | Spark Core |
|
2 | Spark SQL |
|
3 | Spark Streaming |
|
4 | MLlib |
|
5 | GraphX |
|
6 | SparkR |
|
Features of Spark for Data Science
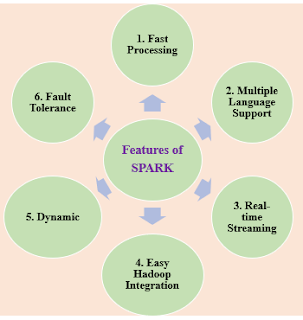
Data Science with Spark
Apache Spark is well suited to handle unstructured information by providing a scalable distributed computing platform. In Data Science, it is used in the field of Text Analytics.
Techniques that are supported by Spark for text analytics can be described as–
Another important path of Data Science that is supported by Spark is Distributed Machine Learning. To
support machine learning operations, Spark provides MLlib subproject.
Algorithms that are available within the MLlib project are –
Classification
Regression
Collaborative Filtering
Clustering
Decomposition
Optimization Techniques
Summary
Apache Spark is an ultra-fast, distributed framework for large-scale processing and machine learning. To support Data Science, it provides subprojects like MLlib, GraphX and also perform text analytics. It enhance the functionality of its machine learning library by adding features like Streaming and SQL services.
Thus, Spark is an idyllic platform for Data Science operations.
Author:
Assistant Professor
Department of Computer Science and Engineering
KIET Group of Institutions, Ghaziabad
Resources:
https://towardsdatascience.com/best-data-science-tools-for-data-scientists-75be64144a88
https://www.researchgate.net/publication/339176824_Apache_Spark_A_Big_Data_Processing_Engine

Thank you for providing this article really appreciate the way you have put down the information if you want you can check
ReplyDeletedata science course in bangalore
data science course